

Meta AI Proposes Multi-Token Attention (MTA): A New Attention Method That Boosts Accuracy by 67%




Have you ever solved a puzzle? But can you put the puzzle pieces together by looking at one piece at a time?
You will end up confused, mixing all the pieces, and will probably take more time to understand and solve the puzzle. This is what happens with traditional attention mechanisms, which only consider one pair (two words) at a time, leading LLMs to miss out on the bigger picture. The bigger picture gives us clarity, context, and relevance, which enables us to find and put the pieces in their right places.
Traditional attention mechanisms handle each word in isolation, making it difficult for the models to understand interactions, semantic meaning, and relations. How does this impact LLM performance?
- Hard to capture interactions that span multiple tokens simultaneously
- Limits the model’s ability to understand phrases or expressions
- Limited Integration of local context
- Resource-intensive, particularly for long texts, limiting its efficiency and scalability
- Higher computational costs
- Inefficiencies due to model complexity
Meta AI has proposed an innovative approach to resolve these issues with its Multi Token Attention mechanism (MTA). Instead of looking at one word at a time, MTA applies a technique called convolution to group multiple words and analyze their relationships. It also allows different attention heads (which look at different aspects of language) to share information more effectively.
Let’s dive into more details.
Challenges With Traditional Attention Mechanism
Imagine reading a book but only focusing on one word at a time instead of phrases or sentences. Traditional attention mechanisms in AI work like this: they analyze relationships between individual words (e.g., "Alice" and "rabbit") but struggle to connect multiple words that together define context.
Why It Fails:
- Traditional attention calculates relationships between one pair of words at a time.
- It’s like trying to solve a jigsaw puzzle by looking at one piece—you miss the bigger picture.
- Scaling this up (to handle more words) makes models slower and more complex.
Here are the top 5 challenges with traditional attention mechanisms in Large Language Models:
Single-Token Focus:
Traditional attention computes relationships by pairing one query token with one key token. This means it handles each word in isolation, making it hard to capture interactions that span multiple tokens simultaneously.
Example: Identifying sentences that mention both “Alice” and “rabbit” is challenging because the mechanism only evaluates one word pair at a time.
Difficulty Capturing Multi-Word Dependencies:
Because attention scores are computed individually for each token pair, it can miss the broader context formed by groups of words. This limits the model’s ability to understand phrases or expressions where the combined meaning is important.
Limited Integration of Local Context:
While self-attention can capture global relationships, it might not effectively aggregate information from nearby words that need to be understood together. This local integration is crucial for nuanced meaning.
Scalability and Computational Cost:
Traditional attention has quadratic complexity relative to the sequence length (each token compares with every other token). This makes it resource-intensive, particularly for long texts, limiting its efficiency and scalability.
Parameter and Complexity Constraints:
Enhancing traditional attention to capture multi-token relationships often requires increasing model complexity and parameters. This can lead to inefficiencies, higher computational costs, and potential challenges in training stability.
Each of these challenges motivates innovations like Multi-Token Attention, which aims to overcome these limitations by integrating multiple token signals simultaneously.
Meta AI’s Solution: Multi-Token Attention (MTA)
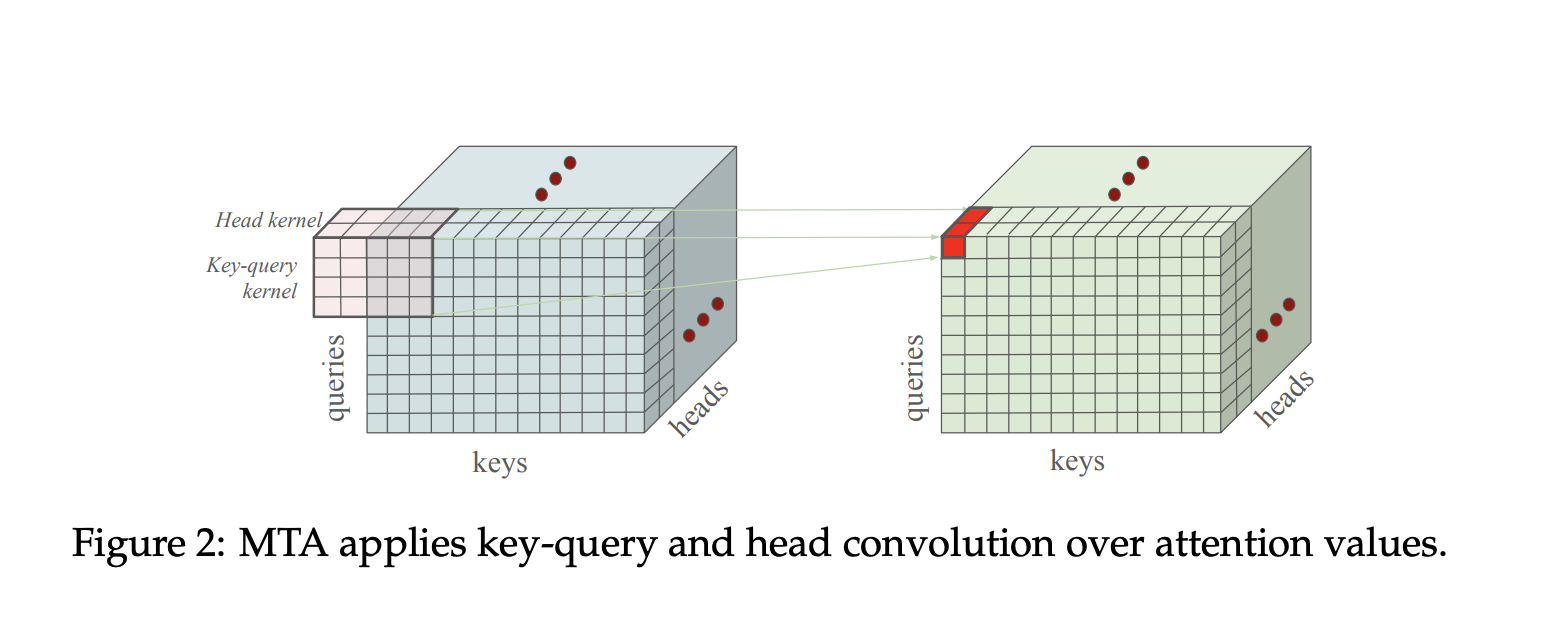
MTA works like putting on glasses that let the AI see groups of words at once. Instead of analyzing words in isolation, it uses convolutional filters (like those in image recognition) to detect patterns across multiple words and attention heads.

How MTA Works?
- Key-Query Convolution:
Looks at nearby words (e.g., "Alice," "rabbit," "blinked") together, like scanning a sentence in chunks.
Example: In the sentence above, MTA recognizes that "blinked" affects both "Alice" and "rabbit."
- Head Mixing Convolution:
Shares insights across different "perspectives" (attention heads). Imagine a team of experts discussing a problem—MTA lets them collaborate.
Example: One head focuses on characters ("Alice"), another on actions ("blinked"), and a third on objects ("rabbit"). MTA combines these perspectives to infer that the rabbit vanished because Alice blinked.
- Stability Tricks:
Uses techniques like group normalization to prevent the model from getting "confused" when processing many words at once.
Key Benefits Of Meta AI’s Multi-Token Attention (MTA)
Below are its key benefits, supported by technical innovations and empirical results:

1. Enhanced Contextual Precision
Problem: Traditional attention mechanisms analyze one token at a time, making it difficult to capture relationships between multiple tokens. For example, identifying a sentence containing both "Alice" and "rabbit" requires integrating signals from both tokens, which standard methods struggle with.
MTA Solution:
- Key-Query Convolution: Applies a sliding window (convolution) to attention logits before normalization, allowing adjacent tokens to influence each other. This helps detect multi-token patterns (e.g., "Alice found a rabbit") more effectively.
- Head Mixing Convolution: Shares insights across different attention heads (e.g., one head focusing on characters, another on actions), amplifying relevant signals while filtering noise.
Impact: In the Needle-in-the-Haystack benchmark, MTA achieved 97.6% accuracy in locating multiple tokens within 4K-token contexts, compared to >50% error rates in traditional models.
2. Improved Efficiency with Minimal Overhead
Problem: Scaling traditional attention to handle multi-token dependencies often requires adding parameters or layers, increasing computational costs.
MTA Solution:
- Parameter Efficiency: MTA introduces only 0.001% additional parameters by reusing existing query/key vectors through convolutional operations instead of expanding dimensionality.
- Lightweight Architecture: The use of grouped normalization and depth-dependent scaling stabilizes training without requiring significant memory or computing resources.
Impact: MTA models process sequences 3x faster in generative tasks like code completion while maintaining accuracy.
3. Superior Long-Context Handling
Problem: Traditional models lose coherence over long sequences (e.g., novels or legal documents) due to fragmented attention.
MTA Solution:
- Extended Context Windows: MTA aggregates local token interactions across 4K-token sequences, enabling it to track relationships (e.g., character arcs in a story) without losing context.
Impact: In tasks like BabiLong (long-context QA), MTA outperformed baselines by wide margins, demonstrating robust performance in document summarization and dialogue systems.
4. Cross-Head Collaboration
Problem: Standard attention heads operate independently, leading to redundant or conflicting signals.
MTA Solution:
- Head Mixing Convolution: Combines outputs from multiple heads, allowing specialized heads (e.g., syntax vs. semantics) to collaborate. For example, one head identifies variable names in code while another checks syntax rules, ensuring aligned outputs.
Impact: This reduces redundancy and improves tasks like code generation, where MTA models achieved 17% higher accuracy on Python coding benchmarks.
5. Training Stability and Scalability
Problem: Deep models often suffer from unstable gradients or information loss in lower layers.
MTA Solution:
- Group Normalization: Stabilizes gradient flow during training by normalizing outputs within attention heads.
- Depth-Dependent Scaling: Adjusts signal strength across layers to preserve critical information in deep networks.
Impact: MTA models trained on 105B tokens showed 15% lower perplexity on arXiv and GitHub datasets compared to baselines, with faster convergence
Conclusion
MTA’s integration of convolutional operations and cross-head collaboration enables LLMs to process multi-token relationships with unprecedented precision and efficiency. BAddressingthe the "single-token bottleneck," it unlocks new capabilities in long-context understanding, code generation, and complex reasoning, all while maintaining computational efficiency. These advancements position MTA as a foundational upgrade for next-generation AI systems.
Link to the paper here.
Need Help? Book a free LLM Strategy Session with me.
I’m here to help. With decades of experience in data science, machine learning, and AI, I have led my team to build top-notch tech solutions for reputed businesses worldwide.
Let’s discuss how to propel your business in my DM!
If you are into AI, LLMs, Digital Transformation, and the Tech world, do follow me on LinkedIn.
Sarfraz Nawaz is the CEO and founder of Ampcome, which is at the forefront of Artificial Intelligence (AI) Development. Nawaz's passion for technology is matched by his commitment to creating solutions that drive real-world results. Under his leadership, Ampcome's team of talented engineers and developers craft innovative IT solutions that empower businesses to thrive in the ever-evolving technological landscape.Ampcome's success is a testament to Nawaz's dedication to excellence and his unwavering belief in the transformative power of technology.
Other Articles
Explore the frontiers of innovation in Artificial Intelligence, breaking barriers and forging new paths that redefine possibilities and transform the way we perceive and engage with the world.






Ready To Supercharge Your Business With Intelligent Solutions?
At Ampcome, we engineer smart solutions that redefine industries, shaping a future where innovations and possibilities have no bounds.
.avif)
